
Hei,
Tämä on kolmas blogini mallinnukseen liittyvästä blogisarjastani. Kirjoitin sarjan ensimmäisen osan tiedon mallinnuksen tasomaisuudesta, toisen osan siihen liityttyvästä käsitteiden määrityksestä.
Tässä kolmannessa ja viimeissä osassa keskityn tilanteeseen, jossa mallinnetaan käytössä olevan tietojärjestelmän tietosisältöä.
Perusjärjestelmien tietokannat mustia laatikoita
Pääpaino tässä blogissa on tietovaraston rakentaminen. Lähtökohtana on se tyypillinen tilanne, jossa on useita operatiivisia perusjärjestelmiä, joiden tietokannan rakennetta ja dataa ei tarkasti tunneta. Ne ovat siis ikään kuin mustia laatikoita.
Tiedot näistä järjestelmistä pitäisi poimia, jalostaa, yhdistellä ja ladata tietovarastoon, jotta niitä voidaan analysoida ja raportoida. Suositeltava ensimmäinen vaihe on laatia järjestelmistä ymmärrettävät, businesslähtöiset käsitemallit. Niiden avulla tiedämme, mitä dataa kussakin järjestelmässä on.
Niiden avulla voidaan rakentaa myös tietovaraston rakenne. Jos siis data saadaan käsitemallin esittämään muotoon, myös raportointi ja analytiikka onnistuvat.
Tavoitteena on mallintaa järjestelmien tiedot ymmärrettävällä, businesslähtöisellä tavalla.
Ylhäältä, alhaalta tai keskeltä
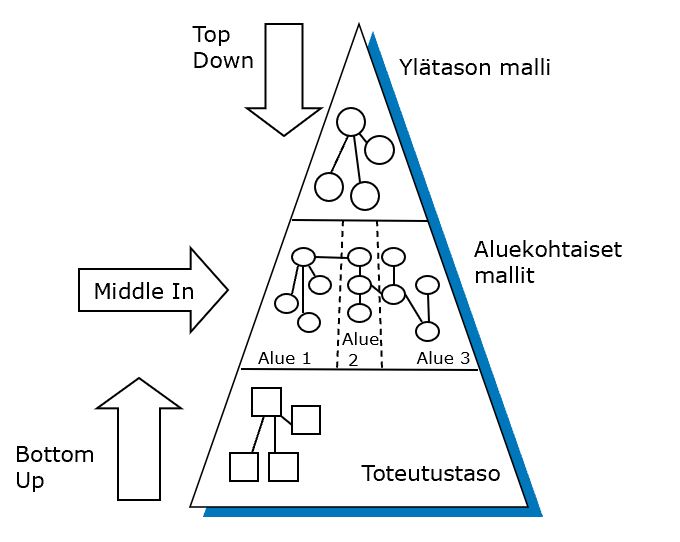
Selvennetään ensin mallinnuksessa käytettävät ajattelumallit Top-down, Bottom-up ja Middle-in.
Bottom-up mallinnus lähtee yksityiskohdista ja niiden mallintamisen kautta päästään käsitemallitasoon.
Käytännössä tämä tarkoittaa tietoaineistojen analysointia ja päättelyä. Tai tutkitaan tietoalkioita eli attribuutteja (kuten asiakasnumero, nimi, katu, laskusumma).
Attribuutteja on kuitenkin valtava määrä. Niiden selvittäminen on kuin rämpisi attribuuttisuossa; se on työlästä ja johtaa usein väärinymmärryksiin, varsinkin jos toimiala ei ole tuttu.
Ns. Data Catalog -tuotteet osaavat automaattisesti kerätä suuren määrän attribuutteja. Ongelmana on kuitenkin, että ne eivät ”ymmärrä” attribuutteja, etenkään käsitteiden kontekstissa. Ne ovat kuitenkin käsitemallinnuksen kanssa erittäin hyödyllisiä työkaluja, joihin kannattaa ehdottomasti tutustua.
Me ihmiset emme ole hyviä isojen, yksityiskohtaisten aineistojen ymmärtämisessä. Se on vähän kuin tulisimme rakennustyömaalle, jossa on lautoja, ikkunoita ja muuta rakennustarviketta, ja niistä pitäisi päätellä minkälainen talo tehdään.
Top Down
Top down -lähestymistavassa lähdetään ylhäältä päin, pääkäsitteistä. Näitä ovat esimerkikisi asiakas, tuote, tilaus ja organisaatioykskkö. Tai terveydenhuollon puolella potilas, yksikkö, diagnoosi, toimenpide.
Ongelmana top-down -ajattelussa on, että vaikka se on hyödyllistä antaen kokonaiskuvan, se jää kuitenkin liiankin ylätasolle. Voi myös tulla tehneeksi vääriä olettamuksia datasta, jos ei tutkita tarkempaa tasoa.
Suoraan Top Down -menettelyllä aloittamisessa on myös vaikeaa osata päätellä mitkä käsitteet ovat nimenomaan ylätason käsitteitä.
Ylätason mallit ovat erittäin tärkeitä ja hyödyllisiä. Ne kannattaa laatia aloittamalla Middle In ja pelkistämällä sitten ylätason mallit.
Middle In
Middle in -lähestymistapa on näistä toimivin ja siis suositeltava menettely.
Kuten todettiin, on vaikea hahmottaa isoja yksityiskohtaisia aineistoja bottom up. Sen sijaan kokonaisuuksien hahmottamisess me ihmiset olemme hyviä. Juuri näin teemme Middle-in -mallinnuksissa.
Mietimme siis käsitteitä ja laadimme ensin käsitemallin (piirustukset). Näin meillä on paikat, joihin ripustaa attribuutit (vrt. rakennustarvikkeet).
Tarvitaan siis perusrakenne ensin, johon voidaan kiinnittää yksityiskohdat.
Middle in -lähestymistavassa mallinnetaan alue kerrallaan suhteellisen tarkalla käsitetasolla. Voidaan välillä tehdä sukelluksia pohjalle, eli tarkastetaan esim. järjestelmän käyttöliittymistä miltä data näyttää.
Välillä voidaan myös tarkistaa, että ollaan organisaation ylätason mallin ja sen rakenteiden kanssa synkroonissa (jos sellainen jo on). Ei siis esim. käytetä uutta termiä nimike, jos ylätason mallissa on päädytty käsitteeseen tuote.
Tässä menettelyssä voi siis tarkistaa alaspäin sukeltamalla ja toisaalta pelkistää ylöspäin ylätason malliksi.
Perusjärjestelmien tietosisällön selvittäminen
Operatiivisten järjestelmien tietokannoissa on usein valtavasti tauluja ja sarakkeita. Näiden tietokantojen rakenteiden suunnittelussa ei ole ajateltu helppoa raportointia ja kyselyä.
Niiden toteutuksessa on satsattu siihen, että järjestelmä on helppo installoida kaikenlaisille asiakkaille. Saattaa jopa olla niin, että uuden asiakkaan tullessa perustetaan uusi taulu. Kaikki tämä monimutkaistaa tietokantaa.
Osa attribuuteista liittyy järjestelmän tekniseen rakenteeseen ja operatiiviseen pyörittämiseen. Niitä ei haluta tietovarastoon.
Tietojärjestelmien tietokannoissa asioita yleistetään ja käytetään omaa terminologiaa. Esimerkiksi kaikki tuotteet, raaka-aineet jne talletetaan nimike-tauluun. Asiakasta kutsutaan termillä Account. Ongelmana on, että liiketoiminta käyttää eri termejä ja käsitteitä.
Yhteen liittyviä asioita pirstaloidaan. Esimerkiksi asiakkaan nimi ja puhelinnumero saattavat olla omissa tauluissaan, voimassaoloajoilla varustettuna.
Haku on nyt vaikeampaa: asiakkaan tietoja ei saadakaan yhdestä taulusta. On tehtävä usean taulun liitos.
Perusjärjestelmissä saattaa siis olla tuhansia tauluja ja tietysti vielä enemmän sarakkeita eli attribuutteja.
Toimittajat eivät useinkaan julkaise järjestelmiensä tietokantojensa tietomalleja. Ne ovat liikesalaisuuksia.
Miten sitten avata tällainen musta laatikko, miten kuvata ja ymmärtää mitä tietoja ja tietojen välisiä riippuvuuksia siellä on?
Kuvataan perusjärjestelmän tietokanta käsitemallina
Kannattaa laatia järjestelmäkohtaisia käsitemalleja, jotka siis kuvaavat ko järjestelmien tietokantoja loogisella tasolla ja liiketoimintalähtöisesti. Esimerkiksi asiakkaan moneen taluluun pirstaloituneet tiedot kuvataan käsitemallissa yhdellä käsitteellä.
Mallinnusta kannattaa tehdä yhteistyössä ko järjestelmän tuntijoiden ja liiketoiminnan edustajien kanssa.
Mallinnuksen kohdealue on siis tietojärjestelmä – siellähän ne datat ovat. Käytetään kuitenkin liiketoiminnan käyttämiä käsitenimiä.
Laaditaan looginen, ymmärrettävä malli. Ei siis kuvata järjestelmän tietokannan teknistä rakennetta tuhansine tauluineen.
Lisätään attribuutit
Käsitemalliin lisätään attribuutit. Yksi tapa selvittää niitä on tutkia käyttöliittymiä.
Eräässä kunnan sotealueen mallinnushankkeessa teimme yhteistyötä pääkäyttäjän kanssa. Hän luetteli terveydenhuollon sovelluksessa näkyviä käyntiin liittyviä attribuutteja: käyntipvm, aloitusaika, hoidon kiirellisyys, jne.
Kirjoitin ne ylös käynti-käsitteen kohdalle, höystettynä selityksillä. Melko pienellä työmäärällä saimme kaikki tärkeät attribuutit liitettyä oikeisiin käsitteisiin. Jos käytetään Ellietä, niin kaikki saadaan dokumentoitua keskitetysti kaikkien saataville.
Lopputuloksena saadaan musta laatikko auki! Siis perusjärjestelmän tietokannan kuvaus vihdoinkin selkeänä ja ymmärrettävänä käsitemallina.
Jo mainitsemani Data Catalog -tuotteet hakevat kyllä attribuutteja koneellisesti, mutta eivät kuitenkaan yllä mainitulla tavalla ymmärrä kytkeä attribuutteja käsitemallitasoon.
Käsitemallista eteenpäin
Käsitemallia tarkennetaan ja valmistellaan vielä tietovarastototeutusta varten. Jos tehdään Data Vault -toteutus, mietitään valmiiksi säännöt, miten käsitemalli muunnetaan Data Vaultin rakenteiksi. Joissakin DW automaatiotyökaluissa on myös automaatiota tähän muunnokseen.
Oma lukunsa on sitten tietojen saaminen ulos perusjärjestelmästä tähän käsitemallin muotoon. Palaan siihen myöhemmin.
Lopuksi
Tässä kuvaamaani menetelmää voi soveltaen käyttää myös, kun laaditaan tietoarkkitehtuuria. Järjestelmäkokonaisuuden hallinnassa on todella hyödyllistä, kun on selkeät kuvaukset kustakin tietokannasta.
Mallinnuksen kohdealue on tässä siis tietojärjestelmä. Lisäksi on tehtävä myös liiketoimintalähtöistä mallinnusta sekä ylätason malli ns. enterprise model. Tässä kuvattua mallia on peilattava näihin malleihin. Näin tietovaraston rakenne heijastelee liiketoiminnan näkemystä käsitteistä ja rakenteista.
Koska meidän tärkeät datamme kuitenkin ovat tietojärjestelmien tietokannoissa, kannattaa käyttää kuvaamaani menetelmää. Näin saadaan selville mitä dataa meillä missäkin on ja mikä on järjestelmien tietokantojen looginen rakenne, liiketoimintalähtöisesti.
Ystävällisin terveisin,
Ari Hovi
Ps. Meillä on ilo tarjota suositun MDM & Data Governance gurun Mike Fergusonin uusi kurssi:
Centralised Data Governance of a Distributed Data Landscape 11.04.2022 – 12.04.2022
Tänä päivänä monet yritykset ja organisaatiot toimivat ns hajautetussa datan hallinnan ympäristössä. Dataa prosessoidaan lukuisissa on-prem, -pilviratkaisuissa sekä ”edge”-systeemeissä. Näissä olosuhteissa relevantin datan löytäminen ja hallinta muodostuu äärimmäisen vaikeaksi. Tämä kahden päivän etäkoulutus antaa sinulle eväät parhaiden käytäntöjen soveltamiseksi omassa organisaatiossasi, tule siis mukaan!
Lisätiedot ja ilmoittautuminen tästä.


