
Ari Hovin artikkeli TIVI-lehdessä:
Yhä useampi yritys käyttää Hadoopin hajautettua tiedostojärjestelmää Big Data –tyyppisille aineistoille. Hadoopilla on ikää vasta n 10 vuotta, mutta se on nopeasti saanut jalansijaa, aluksi luonnollisesti isommissa yrityksissä. Etuja ovat relaatiokantoja parempi skaalautuvuus ja kyky tallettaa kaikenlaisia, myös ei-strukturoituja tietoja. Monille on tärkeintä ”Hadooponomics” eli kustannustehokkuus.
Hadoopin käyttö oli alunperin hankalaa funktioiden käyttämistä ja Java-ohjelmointia. Tietovarasto- ja BI –alueen asiantuntijat olivat tottuneet helppokäyttöisiin työkaluihin ja kätevään SQL-kieleen. Oli kuitenkin suuri tarve saada Hadoopiin kertyneet datat päivänvaloon, mukaan raportointiin. Analytiikkaboomin mukanaan tuomat data-analyytikot halusivat myös päästä kaikenlaiseen dataan helposti. Olikin luonnollinen kehityskulku, että Hadoopiin kehitettiin liittymiä tutulle SQL-kielelle.
SQL on IBM:n jo 70-luvulla kehittämä tietokantakieli, jota kaikki relaatiokantatoimittajat edelleen tarjoavat ja jota BI- ja kyselyvälineet tukevat. SQL on ilmaisuvoimainen neljännen sukupolven kieli.
Nyt SQL-Hadoop liittymissä on suorastaan runsaudenpulaa. Tuotteiden vertailussa voidaan ensinnäkin arvioida kuinka laaja SQL-kielen murre on. Toiseksi voidaan tutkia suorituskykyä erä- ja onlinekyselyissä. Kolmanneksi on eroja siinä, minkälaisia Hadoopin sisällä olevia tiedostotyyppejä tuote tukee. Lisäksi monilla SQL-liittymillä voi kysellä Hadoopin lisäksi muitakin NoSQL –kantoja, esimerkkinä MongoDB. Osa tuotteista toimii avoimen lähdekoodin periaatteilla ja osa on perinteisten tietokantatoimittajien tuotepaletissa.
Yleisin SQL-liittymä on avoimen lähdekoodin Hive. Se muodosti alunperin SQL-lauseista MapReduce –eräajoja. MapReducen on ollut levyintensiivisenä hidas ja nyttemin sen tilalle on tarjolla muistinvaraisia, tehokkampia ratkaisuja kuten Tez ja Spark. Nyt Hiveä voi käyttää eräkyselyiden lisäksi myös ajantasakyselyihin. Hive on yleinen mutta etenkin Hortonworksin tarjonnassa tärkeässä roolissa.
Toinen suosittu tuote on Clouderan Impala, joka on loistanut nimenomaan BI- ja OLAP-tyyppisten kyselyiden tehokkuudessa. MapR:n Drill osaa lukea ilman etukäteen määriteltyä skeemaa mm. JSON –tietoja (Schema-on-read). Spark –ohjelmointiympäristöön on tarjolla myös Spark-SQL.
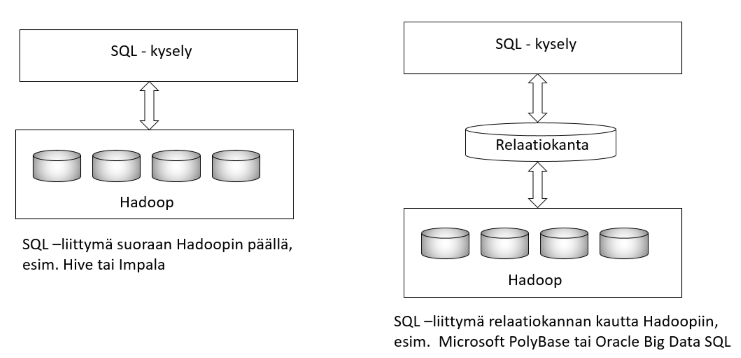
Perinteisillä tietokantatoimittajilla on etuna pitkä kokemus SQL-kielestä. SQL-kyselyt ohjataan näissä ratkaisuissa läpinäkyvästi relaatiokannan läpi Hadoopiin, helpottaen Hadoopin käyttöönottoa relaatiokannan kylkeen. Osa datasta on siis edelleen relaatiokannassa ja laajempi, harvemmin käytetty osa Hadoopissa, ns. Data Lakessa.
Microsoft tarjoaa PolyBase-ratkaisua, jossa käytössä on täysi Transact-SQL –kieli myös Hadoopiin. Oraclen Big Data SQL mahdollistaa kyselyt sekä Oracleen että Hadoopiin saumattomasti. IBM:n ratkaisu on Big SQL, jota on laajennettu ja kehitetty mm. turvallisuusominaisuuksilla. Teradatalla on myös monipuolista tarjontaa.
SQL-Hadoop –tuotteiden kehitys muistuttaa relaatiokantojen alkutaivalta. Niiden suorituskyky parani harppauksin kunnes se riitti vaativiin tapahtumankäsittelyjärjestelmiinkin. Todennäköisesti SQL-rajapintojen laajasta tarjonnasta osa tippuu pois tai yhdistyy muihin.
Big Data-boomi on tuonut mukanaan uutta tiedonhallinnan kehitystä, kuten Hadoop-ekosysteemi. Vanhat parrat eli relaatiomalli ja SQL ovat kuitenkin pitäneet pintansa. JSON-rakenteiden ja muiden ei-taulumuotoisten tietojen lisäksi suuri osa datasta on Hadoopissakin relaatiotaulumuodossa. Uusi Big Data –maailma avautuu parhaiten kyselykantojen veteraanin, SQL-kielen avulla.
SQL – Hadoop testausta
Testasimme Hadoopin kyselyä Hiven ja Impalan SQL-versioilla kirjoittamani SQL-oppaan esimerkkeillä. Osa testeistä tehtiin Amazonin pilvipalvelussa Irlannissa ja osa kannettavalla. Hivessä SQL kyselyistä muodostuu ensin MapReduce –ajoja, jotka vaativat paljon valmistelua johtaen hitauteen. Jos valitsee ”Execute on Tez”, MarRduce ohitetaan ja suoritus huomattavasti nopeampi. Impala-kyselyt olivat alusta saakka nopeita.
Molempien tuotteiden SQL-versiot toimivat jo varsin laajasti. Useimmat käskyrakenteet toimivat täysin samoin kuin muissakin SQL-tuotteissa. Alikyselyissä on joitakin rajoituksia ja Hivessä hieman erilaista muotoilua. Rakenne SELECT … FROM (SELECT … FROM taulu …) … toimii, millä pääsee jo pitkälle.
Testatut ja muutkin SQL-tuotteet kehittyvät nopeasti ja useat rajoitukset ja puutteet ovat poistuneet uudemmissa versioissa. Uusin Hive tukee merkittävänä parannuksena nyt myös talletettuja proseduureja ja käyttäjän määrittämiä funktioita.
Faktalaatikko
Hadoopin tärkeimpiä etuja ovat kustannustehokkuus, skaalautuvuus, ns. time-to-market –nopeus sekä kyky tallettaa ei-rakenteista tietoa.
Hadoop on alkanut yleistyä relaatiokantapohjaisten tietovarastojen rinnalle.
Tarjolla on useita SQL-liittymiä Hadopiin, jotka avaavat tiedot kyseltäviksi, tutuille BI- ja lataustyökaluille sekä analyysikäyttöön.


