
Hei,
Kuvittele tilanne: johtoryhmän palaveri on alkamassa. Toimitusjohtaja haluaa tietää asiakaspoistuman viime kvartaalilta. Analyytikko lupaa toimittaa luvun huomiseen mennessä.
Tämä on BI:n nykytila monessa organisaatiossa. Bisnes kysyy, IT tai data-tiimi rakentaa raportin. Joskus nopeasti, joskus viikkojen kuluttua. Aina kuitenkin pullonkaulan kautta.
Mutta ennen kuin mietitään ratkaisua, pitää ymmärtää, missä ongelma oikeasti on.
Self-service BI — lupaus jota ei ole lunastettu
Kautta datahistorian on yritetty rakentaa niin kutsuttua self-service BI:tä. Sillä tarkoitetaan sitä, että liiketoiminta, sanotaan vaikka myyntijohtaja, joka ei ole IT-osaaja eikä tietovarastoguru, osaisi tutkia omaa dataansa, rakentaa omia dashboardejaan ja saada vastauksia ad hoc -kyselyihin.
BI ja dashboardit mielletään yleensä diagrammeiksi: pylväitä, piirakkaa ja kaikkea, mitä graafikko voi keksiä. Toinen analogia on auton mittaristo — omanlaisensa dashboard, joka kertoo milloin bensa loppuu tai mikä on ajonopeus. Sitten on Excel, jota data-ihmiset vihaavat käyttöliittymänä, mutta jota jokainen bisnes haluaisi käyttää oman alueensa datan tutkimiseen.
Self-service ei ole koskaan kunnolla toteutunut. Harva HR-manager rakentaa itselleen dashboardeja Power BI:llä tai Tableaulla. Syitä on kaksi:
Ensinnäkin data on eri muodossa eri järjestelmissä, ja sen saaminen kyseltävään muotoon edellyttää tiedon mallinnusta, data-alustaa ja IT-ihmistä säätämään. Toiseksi kaikki BI-työkalut ovat suhteellisen vaikeita käyttää, perus HR-manager ei niitä osaa.
Nyt meillä on uusi mahdollisuus: tekoäly voi muuttaa tämän kaiken.
Ensin filosofinen kysymys: kuinka paljon tarvitsemme diagrammeja tai edes Excelin taulukkonäkymää? Jos haluamme tietää asiakaspoistuman tietyltä kvartaalilta, riittääkö meille pelkkä luku, vai haluammeko nähdä diagrammin tai taulukon? Ehkä haluamme historiaa, mutta senkin voisi kysyä: ”vertaa edelliseen kuukauteen”.
Varsinkin ad hoc -kyselyt ovat aina spesifejä, eivät koskaan universaaleja. Asiakkaiden määrä ei kerro paljoa, mutta:
”Kuinka moni tässä lokaatiossa osti hinnannoston jälkeen?” ”Kerro asiakaspoistuma niin, että otetaan vain kanta-asiakkaat mukaan.” ”Mikä oli hävikki viimeisten kahden viikon ajalta tässä tuotekategoriassa?” ”Vertaa myyntiä viime vuoden vastaavaan viikkoon, mutta poista lomaviikot.”
Tässä on yksi tapa jolla ns rikastettu datan mallinnus auttaa asiaa. Kerron miten.
Ongelma ei ole data. Ongelma on merkitys.
Sama kysymys, kolme eri vastausta. Kaikki ovat omasta näkökulmastaan oikeassa.

Kuva 1: Sama kysymys — kolme eri vastausta. Myynti: 1 240 | Markkinointi: 8 900 | Talous: 430
Myynti laskee sopimuksen allekirjoittaneet. Markkinointi uutiskirjeen tilaajat. Talous laskutettavat yksiköt. Tietokannassa tämä näkyy kolmena eri kenttänä: customer_id, client_id, account_id.
Tämä ei ole data-alustan vika. Se ei ole BI-työkalun vika. Se on määritelmien puuttuminen, ja se ongelma toistuu kaikissa mittareissa. Liikevaihto kirjataan joko tilauksen hetkellä, laskutushetkellä tai maksun saapuessa, riippuen siitä, keneltä kysytään. Pelkästään määrittelyllä voidaan tuplata tai puolittaa mikä tahansa mittariluku.
Ennen kuin tiedät mitä mittaat, mittauksilla ei ole arvoa.
Miksi tämä estää AI-pohjaisen self-service BI:n
BI-alalla puhutaan paljon conversational BI:stä tai AI-pohjaisesta self-service analytiikasta. Visio on houkutteleva: bisnes kysyy tietovarastolta luonnollisella kielellä , ”Mikä oli asiakaspoistuma viime kvartaalilla?” , ja saa suoran vastauksen ilman IT-tiimin välikäsiä.
Teknisesti tämä on jo mahdollista. Claude Code, GitHub Copilot, Microsoft Fabric Copilot, kaikki pystyvät muuntamaan luonnollisen kielen SQL-kyselyiksi ja hakemaan tietoa Snowflakesta tai muusta tietovarastosta.
Mutta ne epäonnistuvat systemaattisesti ilman yhtä asiaa: kontekstia.

Kuva 2: Ilman semanttista kerrosta AI arvaa. Semanttisen kerroksen kanssa: oikea vastaus, toistettava, luotettava.
Ilman semanttista kerrosta AI näkee customer_id, client_id ja account_id — ja arvaa. Tulos saattaa olla 8 900, vaikka oikea vastaus olisi 1 240. Väärä vastaus, ei toistettava, ei luotettava.
Semanttisen kerroksen kanssa AI tarkistaa ensin määritykset: Asiakas = sopimuksen allekirjoittaja. Tulos: 1 240. Oikea vastaus. Toistettava. Luotettava.
Semanttinen kerros on se puuttuva palanen, joka erottaa toimivan conversational BI:n hienolta demolta.
Tämän vahvistaa myös maailman suurimpiin tekoälyyrityksiin kuuluva Anthropic omasta sisäisestä käytöstään: he automatisoivat 95 % analytiikkakyselyistään Claudella, mutta vasta sen jälkeen, kun rakensivat semanttisen kontekstikerroksen. Ilman sitä tarkkuus oli 21 %. Claude on myös tässä blogissa kuvatussa ratkaisussa se viimeinen kerros, joka kysyy datalta. Linkki Anthropicin artikkeliin blogin lopussa.
Mikä semanttinen kerros on?
Semanttinen kerros on se kerros data-arkkitehtuurissa, joka yhdistää fyysisen datan ja liiketoiminnan merkitykset.

Kuva 3: Arkkitehtuuri: lähdejärjestelmistä semanttisen kerroksen kautta liiketoimintaan ja tekoälyyn
Alhaalta ylös: lähdejärjestelmissä on raakadata ilman kontekstia. Semanttisessa kerroksessa tapahtuu se olennainen, käsitemallit, määritykset, metadata, omistajuus ja relaatiot yhdistetään fyysiseen dataan. Tämän kerroksen päällä sekä BI että tekoäly käyttävät samoja määrityksiä. Ei enää ristiriitaisia lukuja. Ei enää arvaavia AI-malleja.
Rikastettu datamalli — mitä se tarkoittaa käytännössä
Kun kuulee sanan ’datamalli’ tai ’tietomalli’, useimmat ajattelevat fyysistä skeemaa, tauluja, sarakkeita, indeksejä. Puhun tässä blogissa kehittyneemmästä datamallista. Kutsutaan sitä vaikka rikastetuksi datamalliksi (enriched data model), koska se on jotain laajempaa. Se sisältää käsitemäärittelyt, KPI:t ja niiden laskentalogiikan, liiketoiminnan haastattelun tulokset, omistajuustiedot sekä fyysisten taulujen mappauksen käsitteisiin. Se on yhdistelmä teknistä rakennetta ja liiketoimintakontekstia, ja juuri se konteksti on se, mitä AI tarvitsee.
Semanttinen kerros ei synny työkalusta. Se syntyy mallinnusprosessista, joka etenee käsitetasolta fyysiseen dataan.
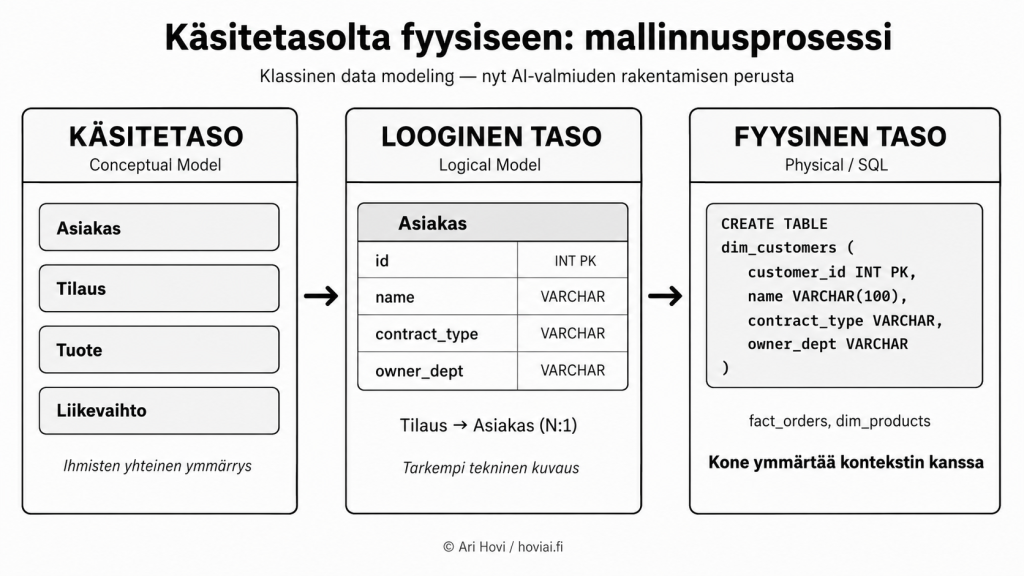
Kuva 4: Käsitetasolta fyysiseen: Conceptual Model → Logical Model → Physical/SQL
Käsitetaso (Conceptual/Semantic Model)
Ihmisten yhteinen ymmärrys siitä, mitä käsitteet tarkoittavat organisaatiossa. Ei puhuta vielä tauluista eikä kentistä, puhutaan siitä, mitä ’asiakas’, ’tilaus’ ja ’liikevaihto’ tarkoittavat. Tämä tieto on kaivettava liiketoiminnalta haastattelemalla, eli workshop tai haastattelu on tehtävä. Ei ole oikotietä.
Looginen taso (Logical Model)
Tarkentaa käsitteet teknisiksi kuvauksiksi: attribuutit, tietotyypit, relaatiot. Asiakas saa kentät id, name, contract_type, owner_dept. Tilaus liittyy asiakkaaseen N:1-suhteella. Kriittinen lisä: KPI:t ja niiden laskentalogiikka kirjataan tässä auki. ’Aktiivinen asiakas’ = customer_id WHERE last_purchase < 90 päivää AND contract_status = active. Tämä on se liiketoiminnan sanakirja, joka syötetään AI:lle kontekstina. Jokaiselle käsitteelle ja KPI:lle määritetään myös omistaja, joka vastaa siitä, että määritys pysyy ajantasaisena.
Fyysinen taso (Physical/SQL)
Käsitemallit linkitetään fyysisiin tauluihin ja sarakkeisiin. CREATE TABLE dim_customers, nimeämiskäytännöt, indeksit. Tässä vaiheessa kone vihdoin ymmärtää kontekstin — ja AI osaa hakea oikeaa dataa oikeasta paikasta oikeilla ehdoilla.
Nämä kolme tasoa on määritelty vain siksi, että prosessi olisi selkeä. Se ei kuitenkaan ole lineaarinen, vaan enemmän iteratiivinen ”ylhäältä alas ja takaisin ylös” tyyppinen prosessi.
Älä osta työkalua ensin — kokeile ensin mvp:tä
Yksi yleisimmistä virheistä semanttisen kerroksen rakentamisessa on se, että lähdetään liikkeelle teknologiasta. Palaverissa kysytään: ”Mitä työkalua käytätte?” Sitten vertaillaan eri ratkaisuja, ja ennen kuin mitään on tehty, ollaan jo hankintaprosessissa. Lähdetään heti miettimään skaalaamista, vaikka ei tiedetä, mitä ollaan skaalaamassa.
Tämä on väärä järjestys. Tee ensin MVP (minimum viable product) jotain, joka tekee suunnilleen sen, mitä halutaan saada aikaiseksi. Käyttäjä saa minimaalisen lisäarvon, mutta sen avulla opitaan nopeasti, mikä toimii.
Jos teillä on jo jokin data-alusta, Snowflake, Databricks, Microsoft Fabric tai muu, teillä on jo enemmän kuin tarpeeksi aloittamiseen. Alustaan liittyvät metadata, taulurakenteet ja olemassa olevat kuvaukset ovat hyviä lähtöpisteitä. dbt:n YAML-tiedostot ovat yksi tapa dokumentoida tätä metadataa, mutta eivät ainoa.
Ensinnäkin opit, mitkä käsitteet ovat oikeasti ongelmallisia, ne, joissa ihmiset ovat eri mieltä. Ne ovat juuri ne käsitteet, joihin semanttinen kerros eniten tarvitaan.
Toiseksi opit, kuinka paljon työtä se oikeasti vaatii. Käsitemallinnusworkshop, jossa sovitaan ”asiakkaan” määritelmä, voi viedä kolme tuntia. Nykyisillä työkaluilla ja tekniikoilla, tämä prosessi ei ole niin pitkä ja vaivalloinen kuin monesti ajatellaan. Esim. erilaisten dokumenttien kääntäminen datamallien pohjiksi onnistuu nykyisin hyvin.
Kolmanneksi opit, mitä työkalu oikeasti tarvitsee tehdä. Kun olet ensin tehnyt sen käsin, tiedät, mitä automatisoida, etkä osta ominaisuuksia, joita et tarvitse.
Kun manuaalinen versio alkaa tuntua liian raskaalta ylläpitää, datamallien on vaikea yhdistää toisiinsa (ovat vain erillisiä diagrammeja), versiopäivitykset vaikeutuvat, niiden jakaminen on vaikeaa, koska kaikki on hajallaan, kun omistajuus on epäselvää, kun linkitys tauluihin katkeaa päivitysten myötä, silloin on aika katsoa työkalua.
Itse edustan sellaista ajattelutapaa, jossa monilla eri työkaluilla ja tekniikoilla voi päästä samaan lopputulokseen.
Teknologiasta lyhyesti — missä semanttinen kerros asuu
Minun on syytä olla rehellinen: olen yksi Ellie.ai:n, datan mallinnustyökalun, perustajista, joten en voi antaa objektiivista arviota siitä, mikä työkalu tähän parhaiten sopii. Jätän sen tietoisesti teidän arvioitavaksenne.
Tämän blogin pointti ei ollut suositella mitään työkalua, se oli kuvata prosessi ja lähestymistapa. Työkalu on toisarvoinen. Se tulee vasta, kun tiedät, mitä tarvitset. Käytän tässä vaan Ellie.ai:ta esimerkkityökaluna. Se voidaan tehdä myös muiden työkalujen avulla.
Mutta koska kysymys tulee aina, ”Okei, mutta missä se semanttinen kerros sitten teknisesti asuu?” , käyn lyhyesti läpi, miten moderni stack voisi toimia.
Nimi semanttinen kerros liittyy alun perin BI:n työkalut mittareihn, eli termi ei ole uusi, sitä on puhuttu jo pitkään. Eli yksi potentiaalinen ehdokas on BI-työkalu. Ne eivät kuitenkaan ole tehty business glosaryksi, tai käsitteelliseen mallinnukseen
Snowflake, Databricks ja Microsoft Fabric rakentavat kaikki omia semanttisia kerroksiaan. Snowflake puhuu Semantic Vieweistä, Databricks Unity Catalogista, Fabric Copilotista ja Power BI:n dataset-kerroksesta. Nämä ovat hyviä ja kannattaa hyödyntää, jos ne ovat jo käytössä.
Rajoite on kuitenkin selvä: ne ovat alustaan sidottuja. Kun mukaan tulee useita ympäristöjä, Snowflake, SaaS-järjestelmiä, legacy-dataa — merkitykset hajoavat uudelleen. Lisäksi ne keskittyvät mittareiden ja dimensioiden määrittelyyn, eivät niinkään liiketoiminnan käsitemalleihin ja käsitteiden välisiin suhteisiin.
Yksi vaihtoehto on dbt yaml filet, eli ns semanttien metriikka voidaan kirjata myös sinne. Mutta se ei ole myöskään tarkoitettu liiketoiminnan käyttämien termien vangitsemiseen. Siinä määritykset tehdään data engineerin YAML:iin, tekninen artefakti, jota liiketoiminta ei pääse ylläpitämään. Siksi sekään ei ole riittävä.
Entä datakataloogi — eikö se ole sama asia?
Ellie.ai pitää sisällään eri mallinnustasot, käsitemallin, loogisen ja fyysisen tason, ja se on suunniteltu juuri käsitteiden ja terminologian ylläpitoon. Ellie.ai voi myös lukea Snowflake- tai Databricks-tauluja ja tehdä mappauksen liiketoiminnan termeihin. Sen avulla voit automatsoida ison osan työlääksi koeotusta käsitemallinnuksesta AI:n avulla
Useat kansainväliset yritykset käyttävät Ellie.ai:ta juuri edellä kuvatun mukaisesti, usein datakatalogien rinnalla. Myös julkisessa keskustelussa semanttisesta kerroksesta datakatalogit tulevat usein mukaan, ja se on luonnollista, sillä niihin on tallennettu paljon tarvittavaa metadataa.
Moni organisaatio ylläpitää jo nyt KPI-määrityksiä ja käsitekuvauksia datakatalogissa, Collibra, Atlan, Microsoft Purview tai muu vastaava. Se on hyvä lähtökohta ja arvokas työ. Mutta datakatalogi ja semanttinen kerros eivät ole sama asia.
Hyvä analogia: kuvittele, että rakennat IKEA-pöydän. Datakatalogi on se lista ruuveista, muttereista ja pöytälevyistä — ja ehkä vielä ohjeet, mistä löydät ne varastosta. Se tieto on tärkeää ja tarvitaan. Mutta se ei vielä kerro, miten pöytä kootaan.
Semanttinen kerros, tai enriched data model, on se kokoamisohje. Se kertoo miten osat liittyvät toisiinsa, missä järjestyksessä ne yhdistetään, ja mitä lopputuloksen pitää näyttää. Ilman kokoamisohjetta voi olla täydellinen lista osista, mutta pöytä ei synny itsestään.
Käytännössä tämä tarkoittaa, että jos organisaatiolla on datakatalogi, se on erinomainen lähtöpiste. Määritykset ja omistajuustiedot ovat jo olemassa, Ne pitää vain täydentää käsitteiden välisillä relaatioilla, laskentalogiikalla ja fyysisillä linkityksillä. Siitä syntyy enriched data model, jota AI voi käyttää kontekstina.
Datakataloogi kertoo mitä on. Semanttinen kerros kertoo miten asiat liittyvät toisiinsa — ja juuri sitä AI tarvitsee.
Näin voisi lähteä liikkeelle
Tässä esimerkki siitä miten semanttinen kerros rakennetaan käytännössä. Tärkeää: tämä ei vaadi tiettyä teknologiaa, Sama lähestymistapa toimii Databricksillä, Snowflakella, Microsoft Fabricilla tai muulla data-alustalla.
01 Liiketoiminnan haastattelu
Ensimmäinen, ja tärkein, vaihe on haastattelu. Järjestetään workshop tai yksi-yhteen-haastatteluja niiden ihmisten kanssa, jotka tuntevat liiketoimintalogiikan. Tavoitteena on selvittää: mistä muuttujista tietty KPI muodostuu, mitä laskentasääntöjä sovelletaan, mitä poikkeuksia ja rajauksia on. Tämä tieto asuu usein ihmisten päissä. Voi olla, että niitä on kuvattu johonkin, mutta siitä huolimatta ne pitää varmistaa liiketoiminnalta, että ne ovat ajantasaisia. Mikään teknologia, menetelmä tai konsepti ei päästä sinua pälkähästä. Liiketoiminnan kanssa on juteltava.
Lopputuloksena syntyy yksikäsitteinen kuvaus siitä, mitä tietty liiketoimintakäsite tarkoittaa ja miten se lasketaan.
02 Semanttinen mallinnus
Haastateltu liiketoimintalogiikka dokumentoidaan rakenteellisesti data modeling -työkaluun. Semanttinen malli kuvaa käsitteet, niiden väliset suhteet ja KPI-laskentasäännöt. Näin tieto ei jää tapauskohtaiseksi, siitä tulee eksplisiittinen, uudelleenkäytettävä määritelmä, jonka liiketoiminta voi lukea ja omistaa.
03 Tietokantarakenteen linkitys
Data modeling -työkalu kytketään data-alustan tietokantaan ja lukee sen rakenteen, taulut, sarakkeet ja tekniset suhteet. Tärkeää: itse data ei siirry mihinkään. Työkalu käsittelee ainoastaan rakennetta. Jos suoraa yhteyttä ei voida tietoturvasyistä muodostaa, asiakas voi toimittaa SQL-luontilauseet manuaalisesti.
04 AI-provider kytkeytyy enriched data modeliin
Asiakkaan valitsema AI-provider, Claude, OpenAI tai muu, kytketään data modeling -työkalun MCP-serveriin. AI saa käyttöönsä sekä semanttisen mallin että tietokantarakenteen. Nyt liiketoiminta voi kysyä luonnollisella kielellä chatissa: ’Mikä on asiakaspoistuma viime kvartaalilta?’
Semanttinen kerros ei ole teknologiaprojekti. Se on liiketoiminnan dokumentointiprojekti — jolla on tekninen toteutus.
Haluatko kokeilla? Enriched data model on lähtöpiste.
Teoria on hyvä. Mutta paras tapa vakuuttaa itsesi, ja johtoryhmäsi, on kokeilla. POC ei ole iso projekti. Se on rajattu testi, jossa enriched data model rakennetaan yhdelle liiketoimintakäsitteelle. Jos tarvitset apua poc:n esittelyssä tai liiketoiminnan vakuuttamisessa, mielelläni tulen avuksi.
Hyvä POC ei yritä ratkaista kaikkea kerralla. Se valitsee yhden kriittisen ongelman, todistaa, että lähestymistapa toimii ja antaa selkeän suosituksen jatkosta. Tässä voimme auttaa, mutta tämä on tehtävissä myös itse.
Lähtökohta on aina enriched data model, ei teknologia. Valitaan yksi rajattu liiketoimintakysymys, rakennetaan sille rikastettu datamalli yhdessä liiketoiminnan kanssa, ja testataan: saadaanko AI:lta luotettava vastaus? Jos saadaan, tiedetään, että lähestymistapa toimii ja voidaan miettiä laajentamista.
Testaa: sama kysymys AI:lle kahdesti
Kysy AI:lta sama kysymys kahdesti: ensin ilman kontekstia, sitten enriched data modelin kanssa. Tulos kertoo kaiken.
Lopuksi
BI-ala on murrosvaiheessa. Data-alustat, kuten Snowflake, Microsoft Fabric ja Databricks, ovat rakentaneet infrastruktuurin valmiiksi. AI-työkalut, kuten Copilot, Claude ja Gemini, ovat valmiina kysymään datalta vastauksia.
Se, mikä useimmista organisaatioista vielä puuttuu, on semanttinen kerros, joka yhdistää nämä kaksi maailmaa: teknisen datainfrastruktuurin ja liiketoiminnan kielen.
Haluan korostaa vielä yhtä asiaa: conversational BI:n rakentaminen ei onnistu ilman liiketoiminnan aktiivista osallistumista. Esimerkiksi myyntijohtajan täytyy saada mukaan määrittelemään, mitä keskeiset käsitteet tarkoittavat. Semanttisen kerroksen rakentaminen perustuu liiketoiminta- ja toimialamääritysten systemaattiseen dokumentointiin, ei pelkästään tekniseen mallinnukseen.
Liiketoiminnan sitouttaminen onnistuu parhaiten silloin, kun ei puhuta teknistä kieltä tai data-alalle tyypillisiä termejä, vaan liiketoiminnan omaa kieltä.
Esimerkiksi myyntijohtajalle asia voidaan sanoittaa näin:
Olemme rakentamassa analytiikkaratkaisua, jossa voit kysyä tekoälyltä suoraan esimerkiksi: “Mikä oli asiakaspoistuma viime kvartaalissa?” tai “Mitkä olivat asiakaskohtaiset katteet vuonna 2025?”
Saat vastaukset chatin kautta ilman, että sinun tarvitsee itse rakentaa raportteja tai etsiä oikeita lukuja eri järjestelmistä.
Mutta jotta tämä toimii oikein, meidän täytyy yhdessä määritellä, mitä esimerkiksi asiakaspoistuma, kate, aktiivinen asiakas tai myynti tarkoittavat juuri meidän liiketoiminnassamme.” Ihan varmasti myyntijohtaan tai muun bisneksen edustajan mukaan tallaisellä myyntipuheella.
Ne organisaatiot, jotka rakentavat semanttisen kerroksen nyt — ennen kuin AI-investoinnit skaalautuvat laajemmin — ovat vuoden tai kahden päästä merkittävässä etulyöntiasemassa.
Ne, joilla semanttista kerrosta ei ole, törmäävät samaan ongelmaan kuin ennenkin: AI arvaa, luvut ovat ristiriitaisia, eikä liiketoiminta luota dataan.
Johannes Hovi
Growth Director, Ari Hovi. Yksi Ellie.ai:n perustajista. Kirjoittaa data-arkkitehtuurista, semanttisesta mallinnuksesta ja AI:n hyödyntämisestä BI-kontekstissa.
Lue myös:
- Semanttinen kerros — mikä se on? → hoviai.fi/blogi/semanttinen-kerros/
- Contextual layer — vanha ongelma uudella nimellä → hoviai.fi/blogi/contextual-layer/
- Anthropic: How Anthropic enables self-service data analytics with Claude → claude.ai/blog/how-anthropic-enables-self-service-data-analytics-with-claude


